5 Building blocks
Models are constructed by connecting several building blocks, where each block represents a distinct, clearly defined task or value. There are different classes of blocks, which are described in detail below.
5.1 Definitions
Definition blocks store the output of a collection of other blocks, such that it can be accessed anywhere else in the model. Several types of definitions exist.
All definitions must be named. Bear in mind that these names must be unique!
5.1.1 Entities and properties
5.1.1.1 Entities
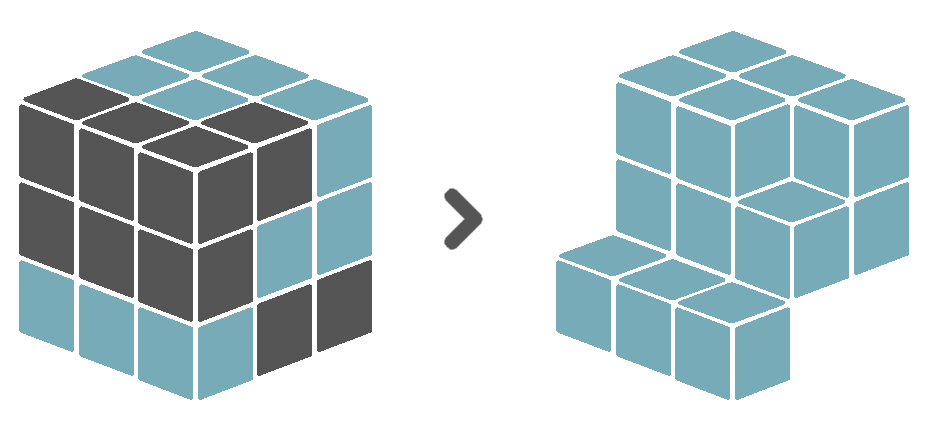
An entity is an identifiable phenomenon of interest in the real world that is not further subdivided into phenomena of the same kind. For example, a lake or a field. The Sen2Cube.at system allows referring to entities at different semantic levels, including water or vegetation. The capability of eventually selecting entities on a higher or lower semantic level depends on the capabilities of the Earth observation sensor, noise during the observation, and the model construction. Entity definitions describe for each observation if it is identified as being part of this type of entity or not in the spatio-temporal extent of the semantic query. For example, when we define the entity water, the entity definition will store a set of boolean observations having a value of True when it was identified as being water, and False otherwise. These observations are aligned along two spatial dimensions. The dimensions are the X and Y coordinates of the observations’ geographical location and one temporal dimension. The time dimension is identified through the timestamps at which the observations were made. Therefore, we call this data structure a cube. See the illustration below, where blue blocks represent observations identified as water, and grey blocks represent observations that were not identified as water.
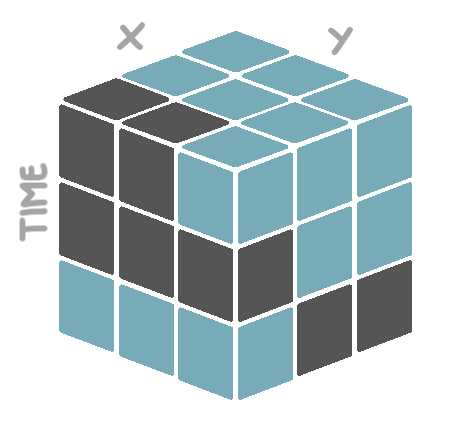
The observations will be associated to an entity type, not an individual entity. This means that observations might be associated with an entity type water, but not to groups of observations that may constitute different water bodies.
5.1.1.2 Properties
Entities are always defined using one or more properties. For example, a property of water may be its blueish colour, but for larger water bodies also its approximate flatness (i.e. a slope of approximately 0%). An entity definition block thus must be followed by one or more property definition blocks. Properties must not be mutually exclusive and should not overlap, i.e., multiple properties will always be connected with AND. Consider a real-world entity lake where three properties * colour, texture, and compactness: They might be fuzzy or optional, but they are not either-or. For example, a lake may appear blue as property colour AND* appear flat as property texture, but is not blue OR flat. There might be situations where one thinks of either-or options in some cases, but this indicates that the property is not defined appropriately and should be solved differently.
Entity definition blocks - and their corresponding property definition blocks - are exclusively used inside the semantic concept dictionary component of the model. In the application component, stored entity definitions can be retrieved, wrangled, and exported.
5.1.2 Results
A result is the output of an inference, while one inference may have more than one results of different types. Depending on the processes that are used in the semantic query, results can be single values, one-dimensional arrays or multi-dimensional cubes. Result definition blocks are exclusively used inside the application component of the model. Stored result definitions can be retrieved at any place within other result definitions inside the same model. Not every result definition needs to be exported. A result definition can also be used as a preliminary output that serves as an intermediate step towards the final output of the semantic query.
5.1.3 Seasons and partitions
5.1.3.1 Seasons
When performing analyses over time, splitting the temporal dimension is a common task. For example, instead of the overall water count, we are interested to know the average water count per season, or the ratio of summer water counts and winter water counts. Seasons that typically appear on temperate latitudes like summer and winter are specified. In Sen2Cube.at, there is the option for different definitions of seasons. For example:
- The harvesting season as the time period from August to October.
- The sowing season as the time period from March to May.
- The rain season as the time period from December to May.
- The dry season as the time period from August to November.
5.1.3.2 Partitions
Distinct but related seasons can then be combined into a partition of the temporal dimension. Like summer, autumn, winter, and spring together form the meteorological seasons, the defined harvesting and sowing seasons can form the agricultural seasons and the rain and the dry season the tropical seasons. As can be seen, the custom-defined partition does not have to fill up an entire year. You are free to define any desired partition, as long as the included seasons span distinct time ranges.
Season and partition definition blocks are considered semantic concepts and are therefore exclusively used inside the semantic concept dictionary component of the model. Unlike entities and results, the seasons and partition definitions are not evaluated at the moment they are defined. The temporal dimension of a cube is only split at the moment a specific season or partition is referenced inside the application component of the model.
5.2 Data and information
These blocks specify the access of the data and information in the factbase, e.g. reflectance values of satellite imagery or semantically enriched information. This is important for defining entities but also, for example, for creating cloud-free mosaics. We separate the available data into the types appearance, atmosphere, reflectance, additional data sources such as topography, and artifacts. Further, some metadata from the Earth observation data can be accessed.
5.2.1 Appearance
The appearance block refers to information about how an Earth observation measurement of the Earth’s surface looks based on an interpretation of what it represents. This can be calculated indices (e.g. multi-spectral greenness indices, multi-spectral brightness values) or categories (e.g. multi-spectral colour spaces/categories) with some level of semantic association. In the case of the Sen2Cube.at system, SIAM-based semantic enrichment generates colour types with low-level semantic association that are accessible using these blocks. This block is mainly used in the Sen2Cube.at system and relates to all land cover and land use questions.
5.2.2 Atmosphere
The atmosphere block refers to all interpretations of measurements or additional information associated with atmospheric phenomena or influences of an image (i.e., not the Earth’s surface). This includes estimates of haze, cloud cover, fog, airborne particulates, etc., that inhibit Earth surface applications or are of specific interest to atmospheric applications. For example, clouds may be treated as noise in most applications related to land cover. However, they might be specifically selected to query for cloud-free images.
5.2.3 Reflectance
The reflectance block refers to calibrated reflectance values (e.g. top-of-atmosphere, bottom-of-atmosphere) of the Earth observations. The reflectance values of the individual bands for a given sensor can be directly accessed using this data block (i.e. calibrated pixel values in each captured band for a given sensor/platform). An example application of this value is to create a cloud-free composite or retrieving the most recent image with less than 10% clouds.
5.2.4 Topography
The topography block refers to any data or information related to the Earth’s topography (e.g. digital elevation models with derived aspect and slope). Example applications might be to separate observations that appear as water or shadow in mountainous areas or to stratify vegetation phenology.
Accessing these data is not yet supported and will be available soon.
5.2.5 Artefacts
The * artefacts* block includes all measurements or interpretations of measurements associated with some errors or noise of invalid measurements (i.e., clouds don’t fall in this category). An example application of this block is creating quality layers with perceived or detected measurement errors or investigating the effects of differences in quality across an image or edges of acquisition swaths.
5.2.6 Metadata
The metadata block includes descriptive and technical metadata of the original satellite images. An example application is to identify the timestamps from individual pixels that contributed to the cloud-free composite if a best-available-pixel approach is used.
Currently, timestamps are the only supported metadata return value.
5.3 Verbs
The core processing blocks are called verbs. Each verb represents a specific action that can be applied to a data cube. Therefore, the verb blocks are labelled with a single action word (i.e. a verb) that describes what the process is doing.
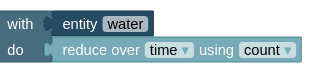
Such an action is always applied to a specific cube, like a stored entity or result definition or some retrieved source data. In terms of blocks, this is modelled by a with-do structure, where a cube is referenced in the with part and the action to be applied to it in the do part. For example, a single reduction over time applied to our defined water entity cube will look like this:
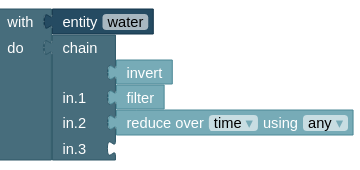
Often, it is desired to apply more than one action to the same cube. This is possible by providing a chain of verbs, where the output of the first process forms the input for the second process, et cetera. For example, start with the water entity cube, invert the True and False values, then keep only the True values, and then reduce that filtered cube over time. Hence, the processing chain is arranged in the logical order of how you also think about the task.
Each verb block is described in more detail below.
5.3.1 Evaluate
The evaluate verb evaluates an expression for each observation in the input cube. An expression is structured as follows:
\[ Expression = (Value, Math Operator, Value) \]
In our case, the left-hand value is an observation from the input cube to which the verb is applied. The right-hand value can be a corresponding observation from another cube, a list of numbers, or even a single number. Since the expression is evaluated for each observation in the input cube, the output of the evaluate block is a new cube with the same dimensions as the input cube.
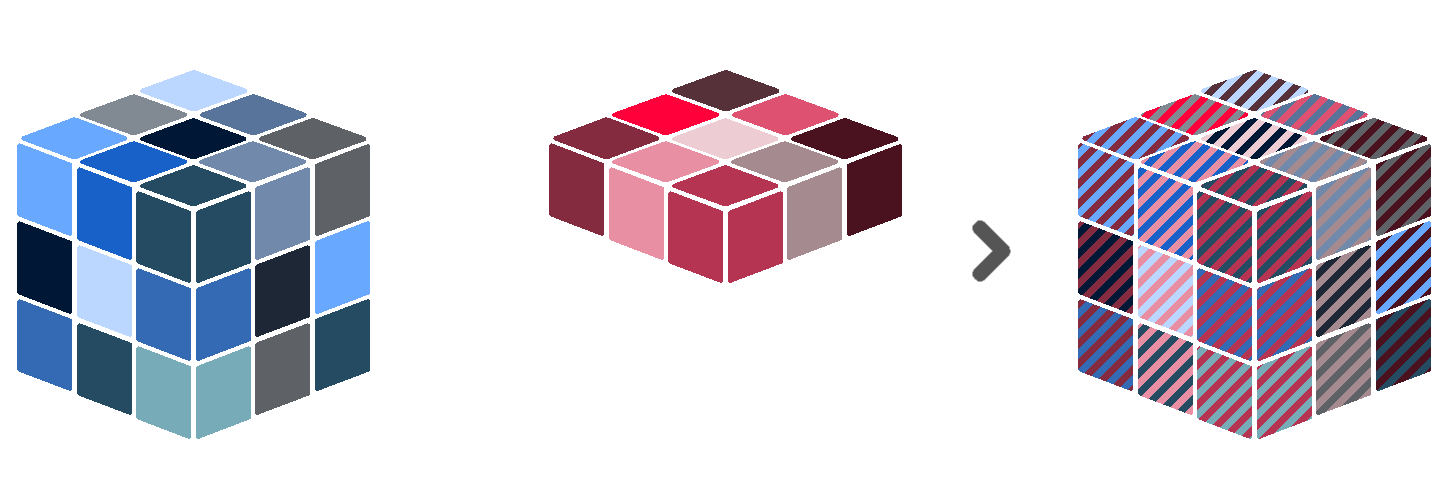
This is illustrated in the figure below. The blue cube on the left forms the left-hand side of the expression, the red cube in the middle forms the right-hand side of the expression. The cube on the right with mixed colours is the output of the evaluation. In this case, the blue and red cube have exactly the same dimensions, meaning that each observation in the blue cube has a corresponding observation in the red cube. Suppose we use the mathematical operator + as our operator. Then, the value of observation #1 - let’s say that is the one on the bottom-left edge - in the output cube equals the value of observation #1 in the blue cube added to the value of observation #1 in the red cube. The same yields for all other observations.

However, the cube on the right-hand side of the expression can have different dimensions than on the left-hand side. For example, consider our cube on the right-hand side has only spatial dimensions. In such a case, the right-hand side values are duplicated for each timestamp in the cube on the left-hand side. This also works the other way around. In jargon, this is called array broadcasting.
The same principle applies when the right-hand side is only a single value. Then, this value is duplicated for each observation in the left-hand side cube.

Sen2Cube.at has several built-in operators that can be used to build expressions.
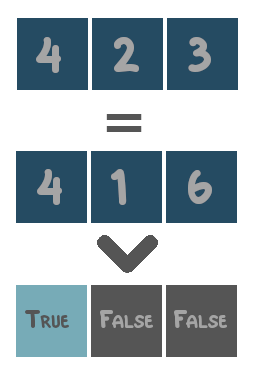
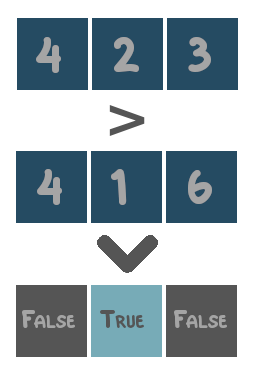
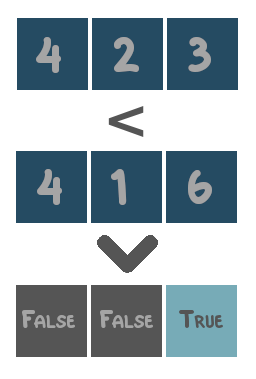
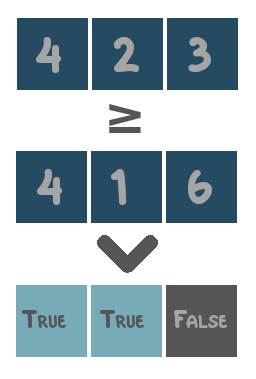
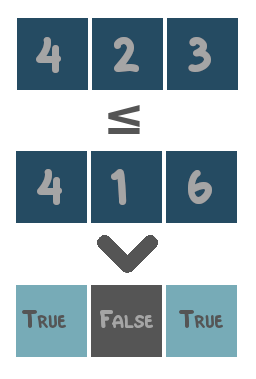
- Comparison operators: operators that compare values and return either
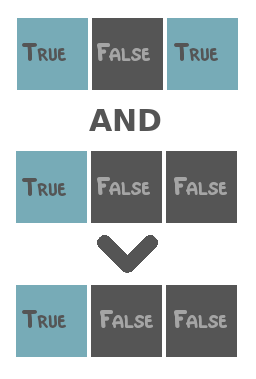
TrueorFalse. These are=,in,>,<,≥and≤. - Logical operators: operators that combine boolean values (i.e.
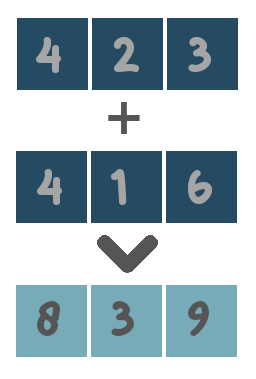
TrueandFalse). These areandandor. - Algebraic operators: operators that combine numerical values. These are
+,-,*and\.
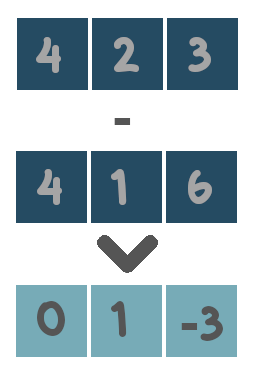
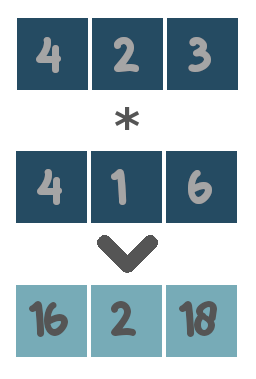
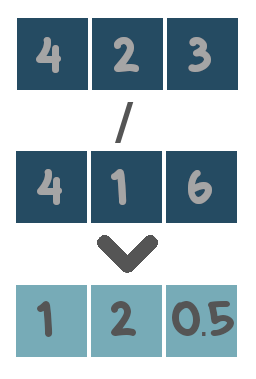
The functionality of each supported operator is illustrated with toy examples below.
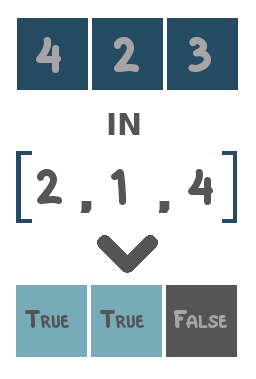
The in operator is special in the sense that each observation in the input cube is compared to a list of values rather than to a single value. If the observed value is in the given list, the result will be True. If not, the result will be False. The same list of values is used for each observation in the input cube.
Be aware of what type of data both sides of the expression contain. For example the logical operators are only applicable when both sides of the expression contain boolean values (i.e. True or False). The algebraic operators only make sense for numerical values and not for categories. …

5.3.2 Filter
The filter verb should only be applied to cubes that contain boolean data values. It then keeps only those values that are True and removes the values that are False. Technically, this is the same as masking (see 5.3.6) a boolean cube by itself.
5.3.3 Group by and ungroup
5.3.3.1 Group by
The group by verb splits the input cube into distinct groups based on a given grouping variable. All subsequent operations will then be applied to each group separately until the ungroup verb is called. At that point, the groups will be combined back together into a single cube. This workflow is also known as Split-Apply-Combine. For example, the input cube can be split into groups such that each group contains exclusively observations from a specific year. Then, these observations can be reduced over time and over space. What is left is a single value for each year. These values can be combined along a new time dimension, in which each time coordinate refers to a year.
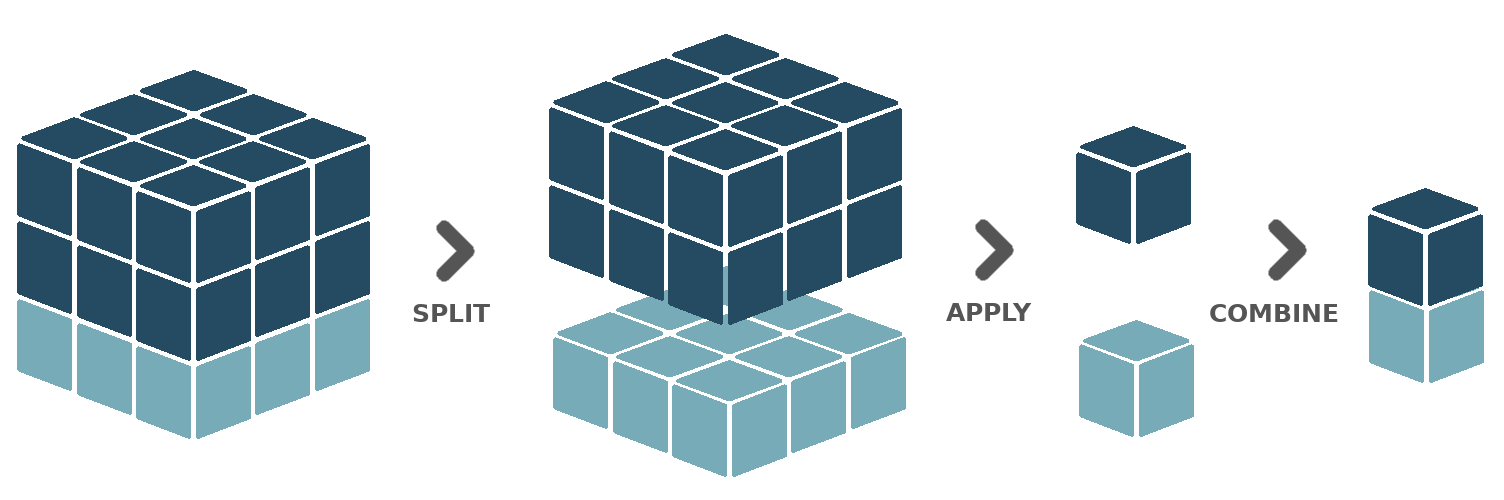
The Sen2Cube.at interface offers several pre-defined grouping variables:
- Temporal grouping variables: grouping variables that will split the temporal dimension, such that each group contains exclusively observations taken within a specific time period. The variables to choose from are
year,season,month,week,dayofyearanddayofweek. - Spatial grouping variables: grouping variables that will split the spatial dimensions, such that each group contains exclusively observations taken within a specific sub-area inside the defined area-of-interest. Currently, only a single variable is supported, named
spatialfeature. This requires the area-of-interest to consist of multiple, distinct spatial features (point, lines or polygons) that do not intersect with each other. Each of these distinct features will then form a group.
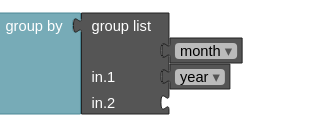
It is also possible to group based on multiple grouping variables. For example, when having two years of data with at least one observation each month, grouping by month will result in 12 different groups. Observations from January in the first year, will end up in the same group as observations from January in the second year. However, when grouping by month and year, there will be 24 different groups. Such multiple grouping operations are enabled in the block interface using a group list block.
Thirdly, you can also provide a defined custom partition (see ??) of the time dimension as a grouping variable.


Currently, the Sen2Cube.at interface does not support cubes with more than one temporal dimension or more than two spatial dimensions. When grouping with a temporal grouping variable, each group represents a specific time period like a year, season or month. When combined back together into a single cube during ungrouping, a new time dimension is created in which each time coordinate refers to one of those groups. Since multiple time dimensions are not allowed, the original time dimension must be reduced before ungrouping — the same yields for spatial grouping operations. The original spatial dimensions must be reduced before ungrouping.
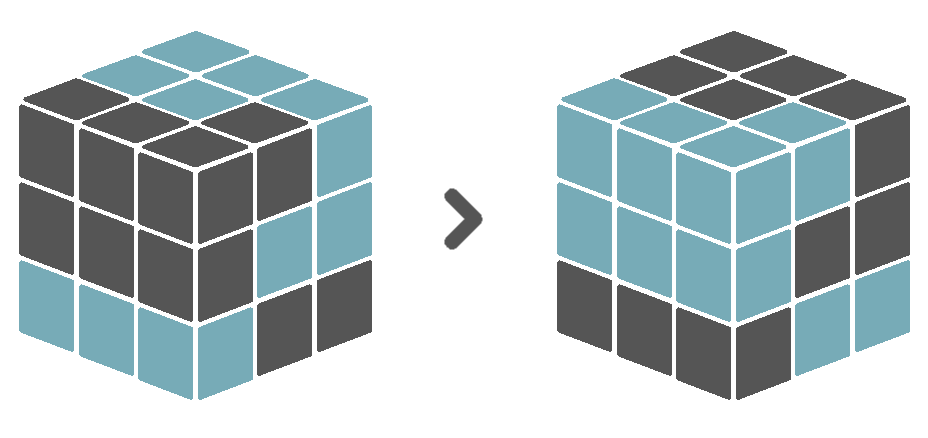
5.3.4 Invert
The invert verb should only be applied to cubes that contain boolean data values. It then replaces all True values with False values and vice versa.
5.3.5 Label
The label verb does not influence the data values in any way. It simply stores a label for the entire input cube. This is useful, for example, before concatenating (see 5.4.1) several cubes over a new dimension. The label of each cube will then serve as the coordinate value of the new dimension.
5.3.6 Mask
The mask verb applies a boolean value mask to the input cube. A boolean value mask is a cube with boolean data values (i.e. True and False). When an observation in the input cube corresponds to a True value in the mask, the observation is kept. However, when an observation in the input cube corresponds to a False value in the mask, the observation is removed.
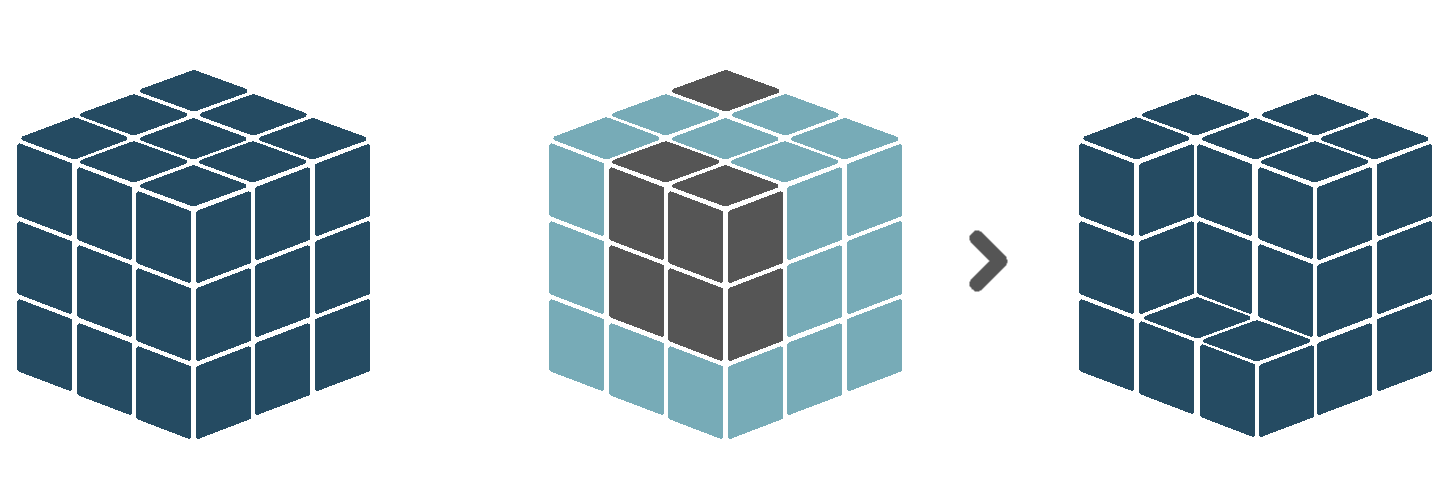
Similar to the evaluate verb, the boolean mask in a masking operation can have different dimensions than the input cube. For example, when the mask only has spatial dimensions, its values will be duplicated for each timestamp in the input cube. When the mask only has a temporal dimension, its values will be duplicated for each spatial location in the input cube.
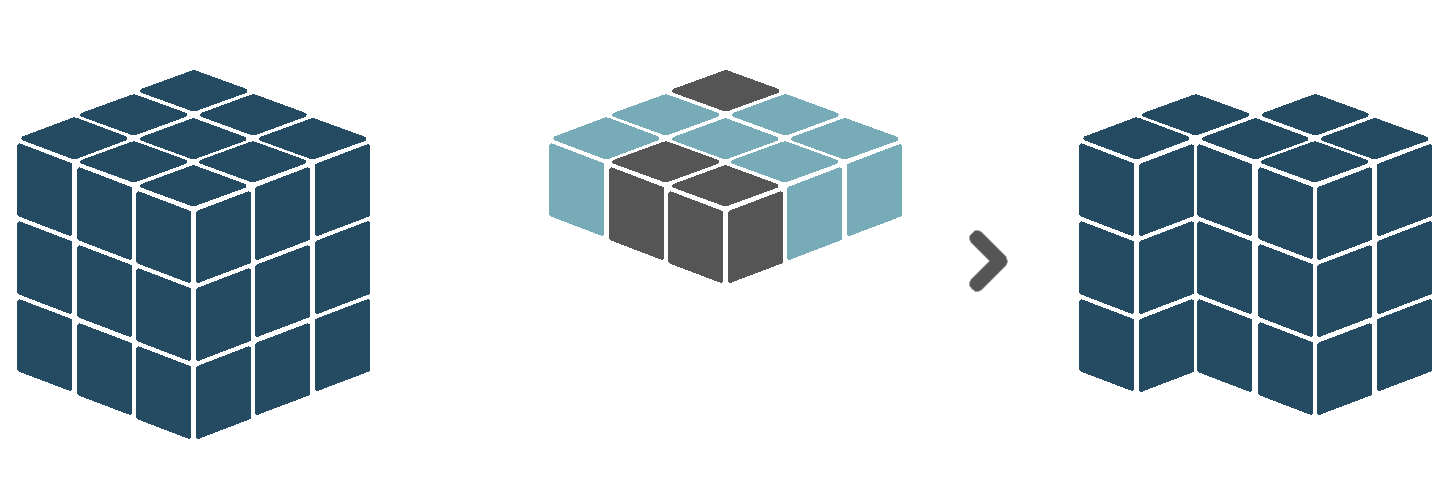
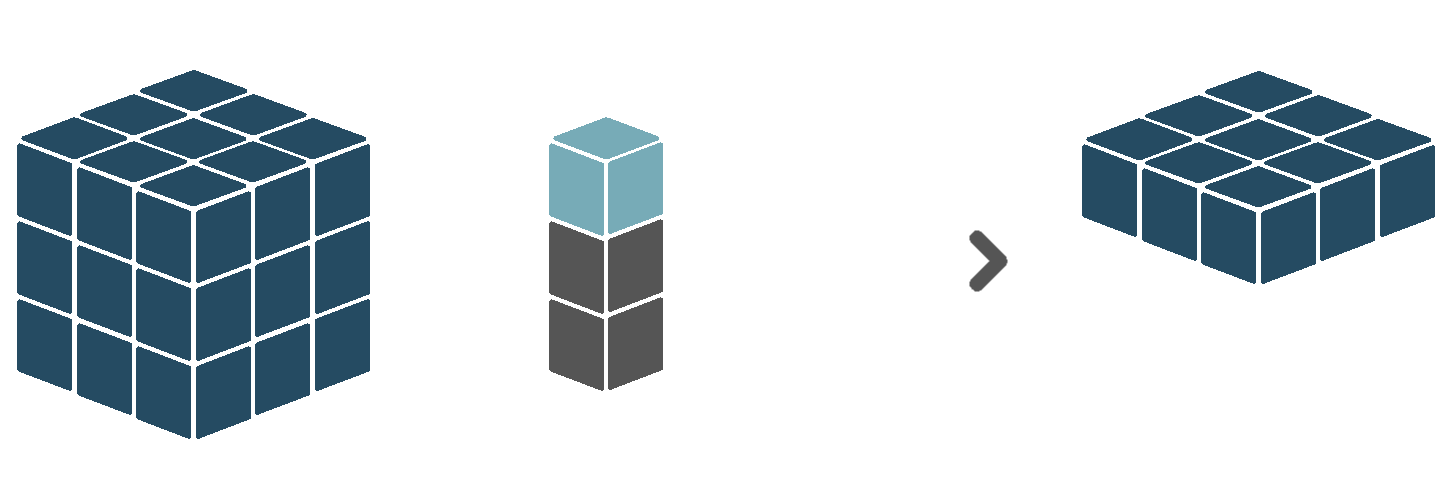
5.3.7 Reduce
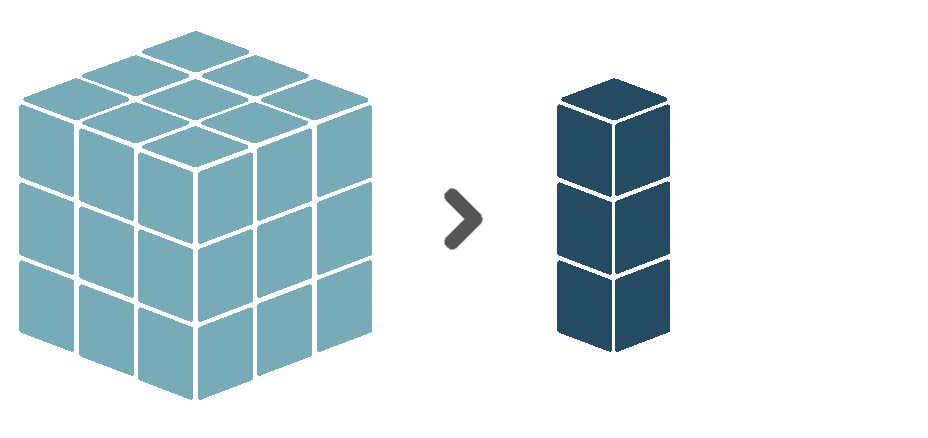
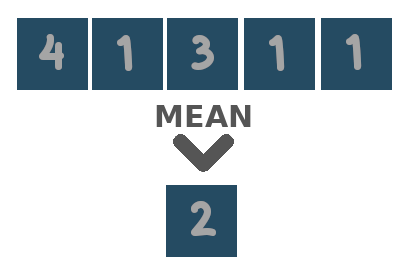
The reduce verb applies a reduction function over a certain dimension or set of dimensions. That means that for each unique combination of coordinate values of all other dimension in the input cube, the values of the dimension(s) to be reduced over are summarized to a single value, based on some function. For example, assume an input cube with one temporal and two spatial dimensions. Basically, this means that for each location in space, we have multiple observations, each made at a different moment in time. When we reduce this cube over the time dimension, using mean as reduction function, we reduce our observed values to only a single value per spatial location, equal to the average of all observed values at that location. This removes the time dimension, leaving us with a cube that only has spatial dimensions.
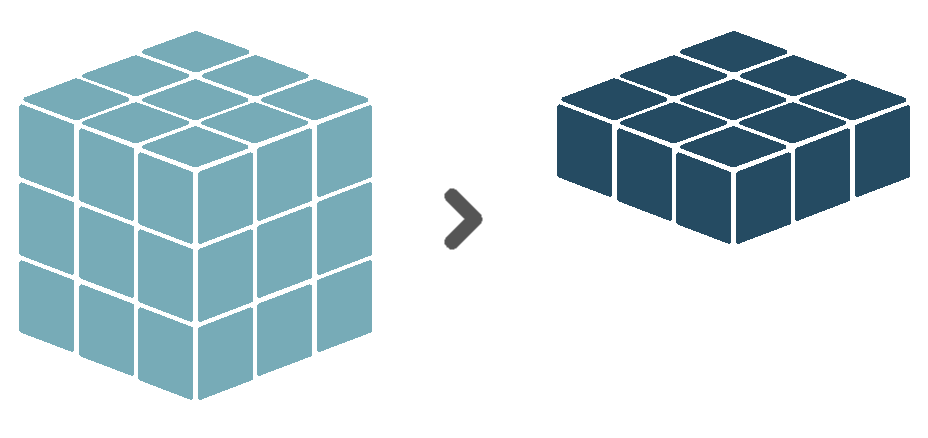
Similarly, we can also reduce the spatial dimensions instead, ending up with a single value per timestamp. The Sen2Cube.at interface only supports the reduction of the two spatial dimensions at once and not of either the X or Y dimension separately.
Sen2Cube.at has several built-in reduction functions that can be used.
Be aware of what type of data and what dimensions both the input cube contains. Some reduction functions are only useful when applied to boolean values (i.e. True and False). Others, for example, calculation of the mean or the sum, make sense for numerical data but not for categorical or boolean data, etc. Also, some reduction functions are only meant to be applied to the time dimension, while others are only meant to be applied to the spatial dimensions.



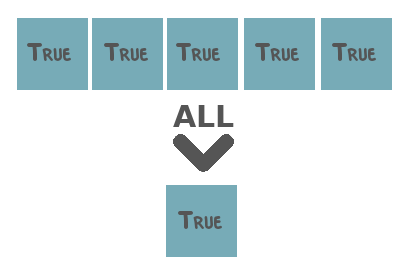
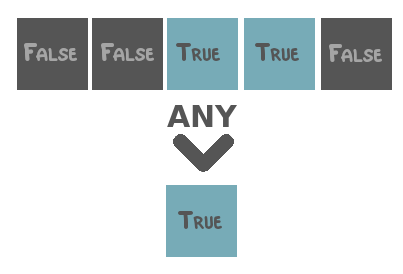


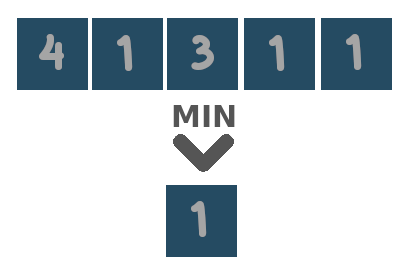
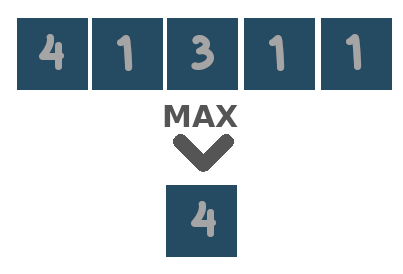



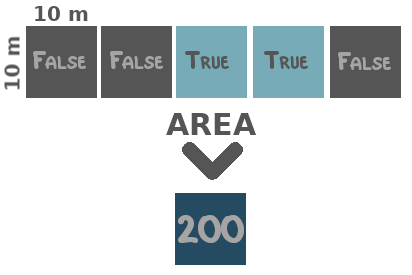
Two special reduction functions are area and duration. The first is meant to be applied to the spatial dimensions and equals the count over space multiplied by the area of a single pixel in square meters. The latter is meant to be applied to the temporal dimension and equals the count over time after resampling the observations to day-level. That is, when there are two observations on the same day, they will be counted as one.

5.3.8 Replace
The replace verb replaces the values of the valid observations of the input cube (so not the missing values!) by the values of the corresponding observations in another cube.
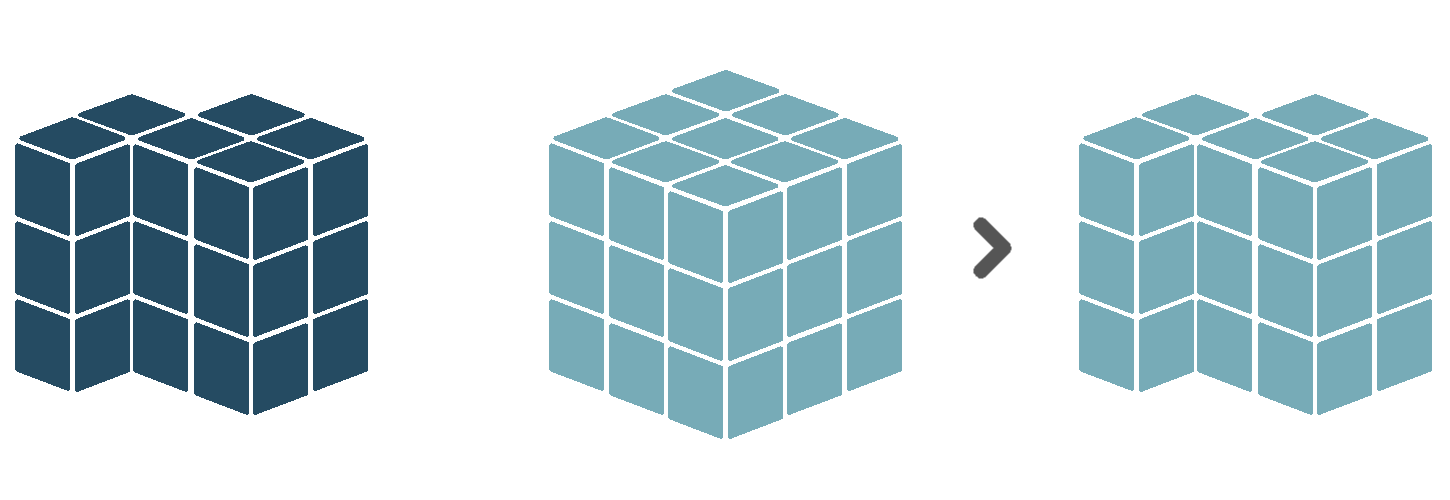
5.3.9 Select
The select verb selects a subset of the coordinates of a certain dimension. It keeps only the observations in the input cube that align to those coordinate values. Currently, only subsetting the temporal dimension is possible. To do so, you can use one or more of the time value blocks (see 5.5), which represent either a time instant, time collection or time period. For example, a select operation could only keep those observations made within the time period between March 2020 and June 2020.
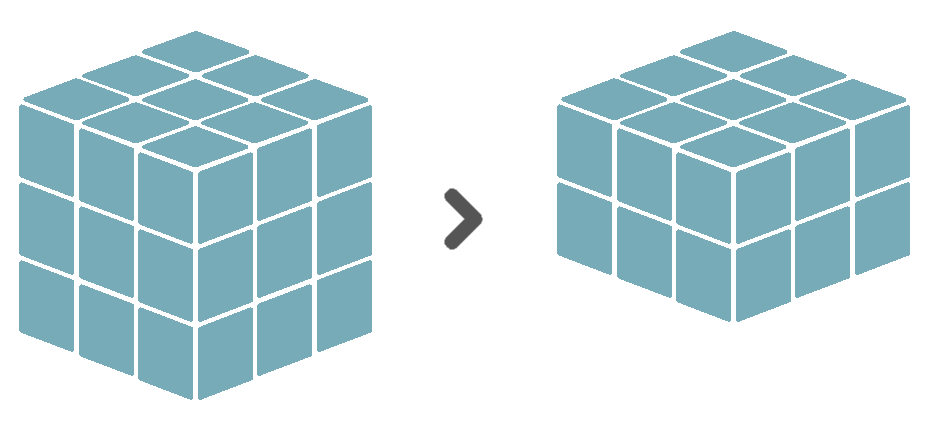
Selection is similar to masking in the sense that they both take a subset of the data. During masking, the subset is defined by another cube containing boolean values. During selection, however, the subset is defined by addressing coordinate values directly.
5.4 Combiners
Verbs are applied to a single input cube, such as a stored entity or result definition or some retrieved source data. However, it is also possible to first combine several cubes together into a single one and then apply verbs to that combined cube. The combiner blocks that facilitate this are described below.
5.4.1 Concatenate
The concatenate combiner combines multiple input cubes along an existing or a new dimension into a single, larger cube. When combining along an existing dimension, this dimension must be present in all input cubes, and all input cubes need to have different coordinate values for that dimension. For example, input cube A has a time dimension with 01-01-2020 and 02-01-2020 as coordinate values. Input cube B has a time dimension with 03-01-2020 as coordinate values. Concatenating the two along the time dimension results in a single cube with a time dimension of length 3, containing 01-01-20, 02-01-2020 and 03-01-2020 as coordinate values.
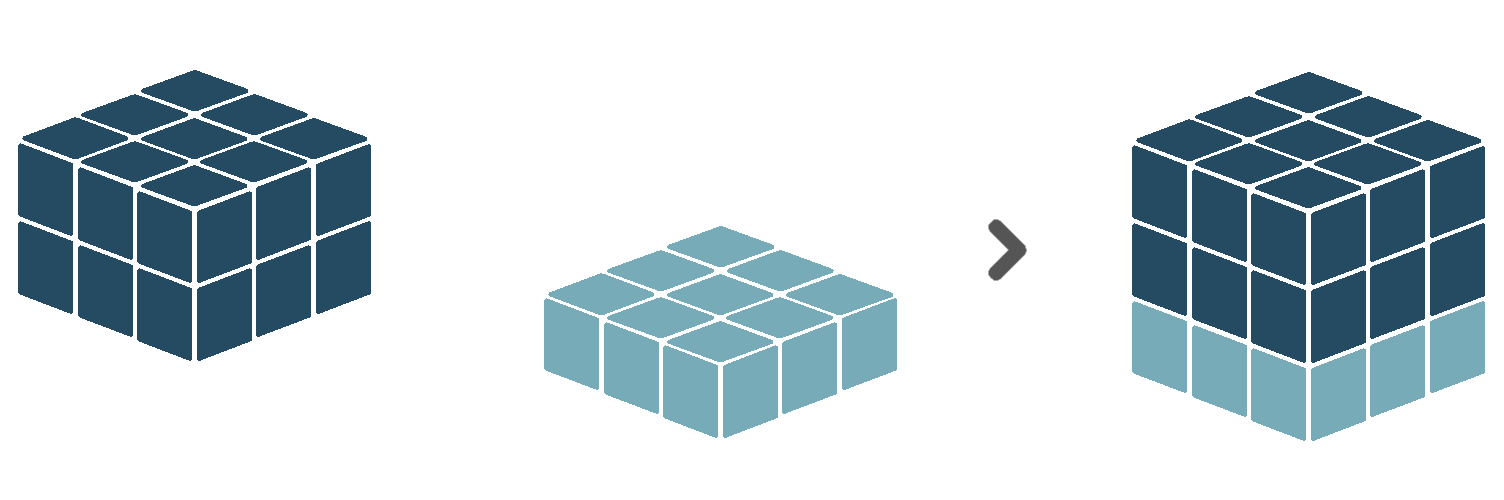
Concatenating along a new dimension will create an output cube with a new dimension, for which observations coming from input cube A will have a coordinate value A, observations coming from input cube B a coordinate value B, etc. What we refer to as A and B will, in practice, be the label (see 5.3.5) associated with the input cube.
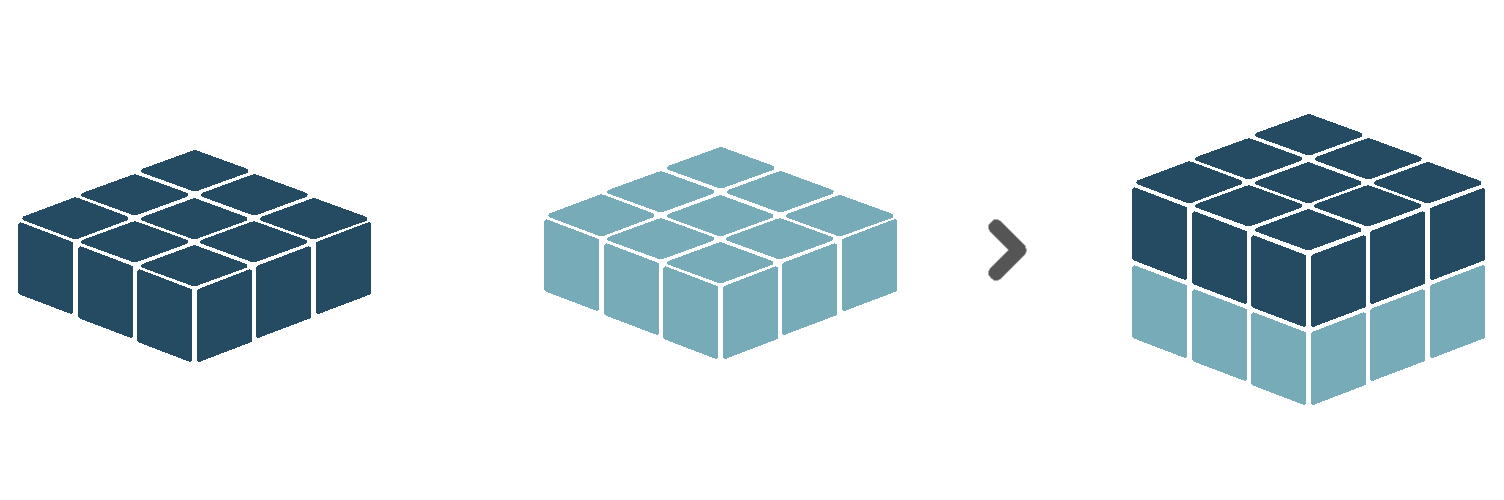
All cubes provided to the concatenate combiner are expected to have matching shapes, except for the dimension to be concatenated.
5.4.2 Compose
The compose combines multiple cubes with boolean data values into a single cube with categorical data values. It requires the input cubes to be distinct. This means, when an observation in input cube A is True, the corresponding observations (i.e. having the same coordinates) in the other input cubes can not be True. Then, the output cube will assign category value 1 to all True-observations of input cube A, category value 2 to all True-observations of input cube B, et cetera.
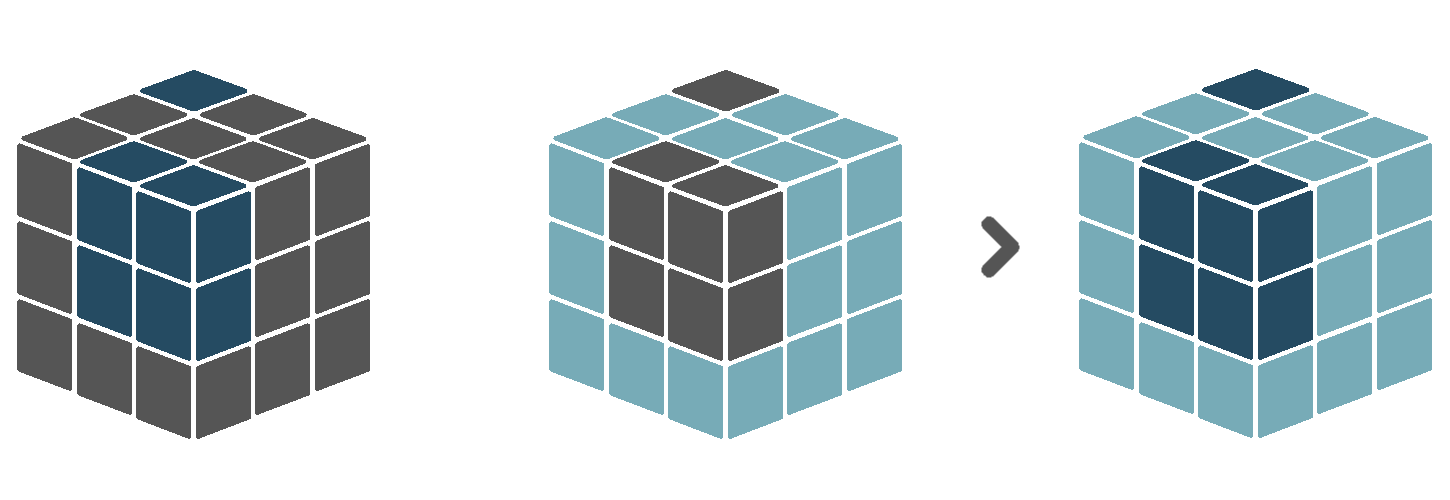
5.4.3 Merge
The merge combiner works the same as the evaluate verb (see 5.3.1) but allows for an expression with more than two variables. For example, cube A + cube B + … + cube n. It offers only logical and algebraic operators. The output cube will always have the same dimensions as the first input cube.
5.5 Time
Time value blocks refer to the temporal dimension of the query. They allow to subset cubes by time, define custom seasons, et cetera. There are three different time value blocks.
5.5.1 Time instant
A time instant is a specific moment in time. It can be modelled with three components: the year, the month and the day. That is, a fully specified time instant can be 2020-07-23. However, not all components need to be specified. One can also leave out the year and create the time instant XXXX-07-23, which will refer to all 23rd of July dates in the overall time interval of the query. Similarly, 2020-07-XX will refer to all days in July 2020, and XXXX-07-XX to all days in July, for all years in the time interval.
5.5.2 Time periods
A time period is a consecutive period of time, defined with a from time instant and a to time instant. The interval is closed at both sides, so both the from and to time instants are included in the time period. It is also possible to use not fully specified time instants. For example, the time period from XXXX-05-XX to XXXX-08-XX is the time period from May to August, no matter the year. Thus, when subsetting the time dimension of a cube with this time period, all timestamps in either May, June, July or August will be selected for each year in the overall time interval.
In a time period, the from time instant should always precede the to time instant. Currently, that means it is impossible to create time periods like [from XXXX-11-XX to XXXX-01-XX], meaning from November to January. To model such a period of time, it is possible to use a time collection instead.
5.6 Space
Currently, there is no support for spatial subsetting of cubes or define custom areas that divide the overall area-of-interest. Such functionalities might be added in the future.
5.7 Comments
The comment block allows you to add comments to parts of your model, such that both your future self and others can better understand what is happening. Comment blocks can be added anywhere in the model and will be ignored during evaluation.
 Another option is to comment a block directly, which can be achieved by a right-click on the block, which opens the context menu, and the click on Add Comment. This option allows to add a comment directly, not only those on the highest level. However, The comment may be hidden if it is not opened and too many comments may overlap each other. The question mark in the blue circle indicates that there is a comment associated to the block. The comment can be deleted by a right-click on the blue circle with the question mark and then click on Remove Comment in the context menu.
Another option is to comment a block directly, which can be achieved by a right-click on the block, which opens the context menu, and the click on Add Comment. This option allows to add a comment directly, not only those on the highest level. However, The comment may be hidden if it is not opened and too many comments may overlap each other. The question mark in the blue circle indicates that there is a comment associated to the block. The comment can be deleted by a right-click on the blue circle with the question mark and then click on Remove Comment in the context menu.
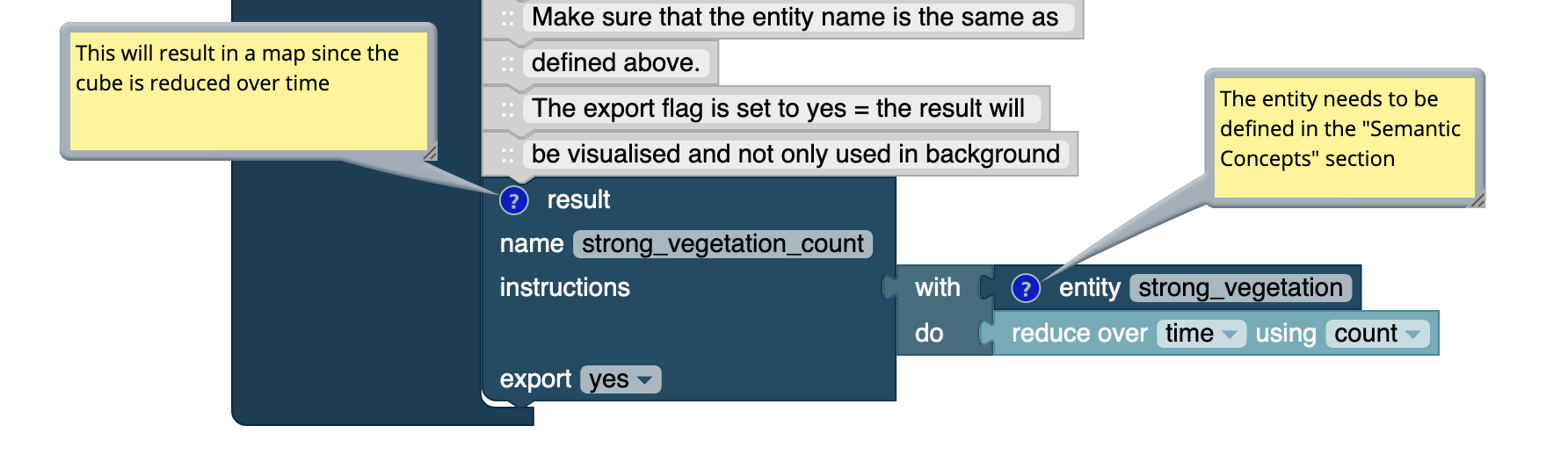
Example of commenting a block directly
Remember that the comment block is not implemented to allow a certain processing in the inference engine or to provide a feature - it is for you. If you spend a lot of time to create a model you may want to avoid doing it again because the model cannot be easily understood anymore! So, similar to a programming or scripting language, it is recommended to provide a good description to the model.
5.8 Disabling blocks
Blocks can be (temporarily) disabled. The inference engine will then ignore the block and all blocks that are directly depending on it. Disabling a block can be done by a right-click on the block and clicking on Disable Block in the context menu.
The blocks, which are disabled will be indicated by a yellow hatch. Of course, it does not make sense to disable every type of block. Disabling a block may even lead to a crash within the inference process. However, it makes sense for an entire entity or result (if they are not referenced later anymore) or a single verb in a chain.
Disabled blocks can be enabled again by a right-click on the block and on Enable Block in the context menu.
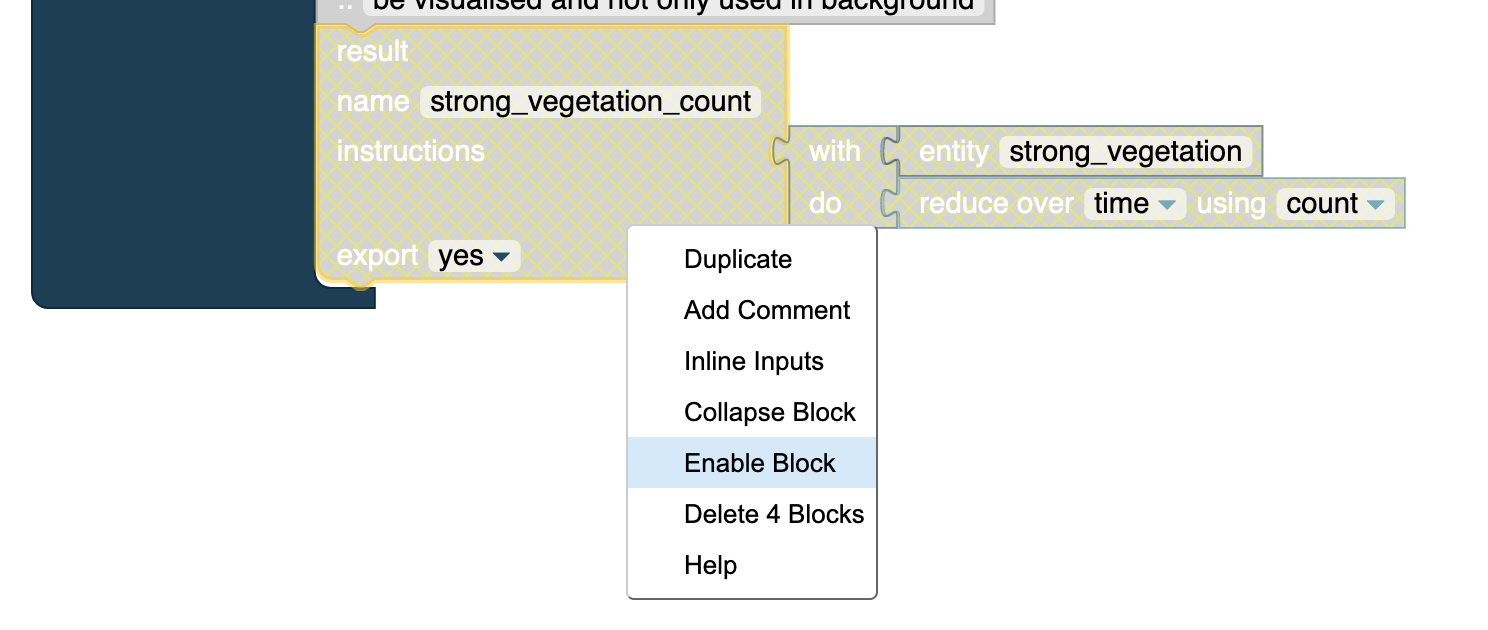
Disabled blocks are indicated with a yellow hatch and will not be executed